One of the cool new features that was introduced with 18.1.0.0.0 was a subtle change in the Exadata storage server patching process. While not required, this new functionality removes the need to use patchmgr to drive Exadata storage server patches. In Juan Loaiza’s Open World session on new Exadata features, this slide jumped out to me:
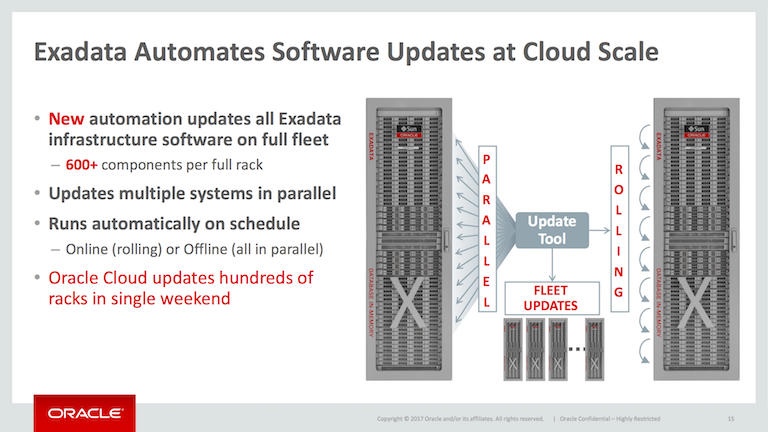
While this slide may look like marketing fluff, this new feature turns out to be pretty cool. The current Exadata storage server patching process looks like this:
- Download patch file to a single server, typically a database server in the rack
- Unpack the zip file, run patchmgr to patch all cells in the rack in parallel, or one cell at a time
This has worked very well for the last few years, but there are a few key issues to this strategy:
- patchmgr requires passwordless access to root on all cells
- When applying rolling patches, the session running patchmgr must be alive the entire time
What Oracle has come up with is a new strategy where you can do the following:
- Stage the patch file in a central location
- Give storage servers the URL to check for new patches
- Set a schedule for when cells will be upgraded
- Storage servers will automatically apply updates when the time comes
This is very useful because it utilizes the asmdeactivationoutcome attribute of grid disks to determine if it’s safe for a cell to be upgraded. This attribute tells cellsrv whether a disk can be safely taken offline. If the ASM redundancy is degraded (whether due to a failed disk or a cell being patched), cellsrv will know to not take the disks offline. Rolling patching via patchmgr will only apply patches to cells sequentially. If you have a large enough cluster, you could potentially be able to take multiple cells offline at once – it’s all up to the partner disk configuration for ASM.
Think about it from Oracle’s perspective – as they increase their footprint of Exadata racks running in the cloud, it’s much easier to be able to patch them via this method. Also, if you have a secure environment with SSH disabled via EXAcli, you have to enable SSH access to apply patches. With the new mechanism, this requirement is no longer there. Exadata storage servers are finally working their way in the the realm of the “appliance.”
What’s new in version 18
In order to accomplish this vision, version 18.1 included a new “SOFTWAREUPDATE” object type to the cellcli shell. After the first upgrade to version 18, there is nothing populated in here:
[root@enkx4db03 ~]# dcli -l root -g cell_group cellcli -e list softwareupdate detail
enkx4cel05: name: unknown
enkx4cel06: name: unknown
enkx4cel07: name: unknown
What if we want to apply an update?
CellCLI> help alter softwareupdate
Usage: ALTER SOFTWAREUPDATE {
VALIDATE PREREQ
| UPGRADE [ FORCE ]
| =
[, = ]...
Purpose: Performs an action or alter attributes for a software update.
Arguments:
attribute_name: attribute to be changed.
attribute_value: new attribute value.
Options:
VALIDATE PREREQ: Download software and run checks.
UPGRADE: Download software, run prereq and upgrade.
FORCE: Ignore prereq failure on upgrade.
Examples:
ALTER SOFTWAREUPDATE time='2017-06-09T11:30'
ALTER SOFTWAREUPDATE VALIDATE PREREQ
The key attributes for “SOFTWAREUPDATE” are:
- name – the patch version number (18.1.1.0.0.171018) that will be downloaded. If left blank, newest version is selected
- store – this URL points to a directory that contains patches
- frequency – how often you want the storage server to poll the store for new patches
- time – the time that you would like the storage servers to patch themselves
- timeLimitInMinutes – how long a cell should wait for other cells to complete patching before starting
It’s important to note that the “store” attribute is not a URL to download that patch itself. Instead, it is a directory that can be browsed. This way, one URL can be used every time – if you put a new patch version in the directory, cells will automatically update based on the schedule and polling frequency. Also, you cannot use the file name as it comes from MOS (p###_version_platform.zip). What you need is version#_patch.zip.
It is worth noting that this functionality was introduced in 18.1.0.0.0, which means that you have to be on this patch level to use this feature. It won’t be able to be tested until a new patch beyond 18.1.0.0.0 is out. Thankfully for us, Oracle released version 18.1.0.0.0 during Open World, and we now have an 18.1.1.0.0.0 with the October quarterly full stack patch. I went ahead and upgraded one of the Exadata racks in the Enkitec lab, and now we can test the 18.1.1.0.0 upgrade with this new process.
How does it work?
I first took the patch file and renamed it to 18.1.1.0.0.171018.patch.zip. I had the file stored on one of my compute nodes, so I fired up an HTTP server using python:
[root@enkx4db03c02 18.1.1.0.0]# ls -al
total 6732287
drwxr-xr-x 2 4294967294 4294967294 6 Oct 27 14:21 .
drwxr-xr-x 7 4294967294 4294967294 7 Oct 24 14:11 ..
-rw-r--r-- 1 4294967294 4294967294 2308711303 Oct 27 14:21 18.1.1.0.0.171018.patch.zip
-rw-r--r-- 1 4294967294 4294967294 2308711303 Oct 24 15:29 p26875767_181100_Linux-x86-64.zip
-rw-r--r-- 1 4294967294 4294967294 1145052023 Oct 24 16:05 p26923500_181100_Linux-x86-64.zip
-rw-r--r-- 1 4294967294 4294967294 1125875673 Oct 24 16:15 p26923501_181100_Linux-x86-64.zip
[root@enkx4db03c02 18.1.1.0.0]# python -m SimpleHTTPServer 80
Serving HTTP on 0.0.0.0 port 80 ...
This works in a pinch, but the URL won’t be available forever. Keep in mind that this isn’t ideal – I’d be better off putting this on a persistent share that all of our Exadata racks can query every 2 weeks or so. If you have a ZFS storage appliance, that would be perfect for this. If I go that route, the cells will be on an automatic upgrade cycle as soon as I put the patch file in that directory. Moving along with the simple python HTTP server, I feed the URL to my storage servers and set a schedule:
[root@enkx4db03 ~]# dcli -l root -g cell_group cellcli -e 'alter softwareupdate store=\"http://192.168.12.111\"'
enkx4cel05: Software Update successfully altered.
enkx4cel06: Software Update successfully altered.
enkx4cel07: Software Update successfully altered.
[root@enkx4db03 ~]# dcli -l root -g cell_group cellcli -e 'alter softwareupdate time=\"10:45PM Monday\"'
enkx4cel05: Software update is scheduled to begin at: 2017-10-30T22:45:00-05:00.
enkx4cel06: Software update is scheduled to begin at: 2017-10-30T22:45:00-05:00.
enkx4cel07: Software update is scheduled to begin at: 2017-10-30T22:45:00-05:00.
What this will do is tell the storage servers to pull down the latest patch version available from http://192.168.12.111. They will pull down the latest version because the “name” attribute was not set. This will be a one-time pull because the “frequency” attribute has been left blank. If I look at the output on my HTTP server, I can see the following:
[root@enkx4db03c02 18.1.1.0.0]# python -m SimpleHTTPServer 80
Serving HTTP on 0.0.0.0 port 80 ...
enkx4cel05-priv1.enkitec.local - - [30/Oct/2017 22:29:59] "HEAD / HTTP/1.1" 200 -
enkx4cel07-priv1.enkitec.local - - [30/Oct/2017 22:29:59] "HEAD / HTTP/1.1" 200 -
enkx4cel06-priv1.enkitec.local - - [30/Oct/2017 22:29:59] "HEAD / HTTP/1.1" 200 -
enkx4cel05-priv1.enkitec.local - - [30/Oct/2017 22:29:59] "GET / HTTP/1.1" 200 -
enkx4cel07-priv1.enkitec.local - - [30/Oct/2017 22:29:59] "GET / HTTP/1.1" 200 -
enkx4cel06-priv1.enkitec.local - - [30/Oct/2017 22:29:59] "GET / HTTP/1.1" 200 -
enkx4cel07-priv1.enkitec.local - - [30/Oct/2017 22:30:44] "HEAD / HTTP/1.1" 200 -
enkx4cel07-priv1.enkitec.local - - [30/Oct/2017 22:30:44] "GET / HTTP/1.1" 200 -
enkx4cel07-priv1.enkitec.local - - [30/Oct/2017 22:30:44] "HEAD /18.1.1.0.0.171018.patch.zip HTTP/1.1" 200 -
enkx4cel07-priv1.enkitec.local - - [30/Oct/2017 22:30:44] "GET /18.1.1.0.0.171018.patch.zip HTTP/1.1" 200 -
enkx4cel05-priv1.enkitec.local - - [30/Oct/2017 22:31:02] "HEAD / HTTP/1.1" 200 -
enkx4cel06-priv1.enkitec.local - - [30/Oct/2017 22:31:02] "HEAD / HTTP/1.1" 200 -
enkx4cel05-priv1.enkitec.local - - [30/Oct/2017 22:31:02] "GET / HTTP/1.1" 200 -
enkx4cel06-priv1.enkitec.local - - [30/Oct/2017 22:31:02] "GET / HTTP/1.1" 200 -
enkx4cel05-priv1.enkitec.local - - [30/Oct/2017 22:31:02] "HEAD /18.1.1.0.0.171018.patch.zip HTTP/1.1" 200 -
enkx4cel06-priv1.enkitec.local - - [30/Oct/2017 22:31:02] "HEAD /18.1.1.0.0.171018.patch.zip HTTP/1.1" 200 -
enkx4cel05-priv1.enkitec.local - - [30/Oct/2017 22:31:02] "GET /18.1.1.0.0.171018.patch.zip HTTP/1.1" 200 -
enkx4cel06-priv1.enkitec.local - - [30/Oct/2017 22:31:18] "GET /18.1.1.0.0.171018.patch.zip HTTP/1.1" 200 -
Sure enough, the packages have been downloaded. If I run that same “list softwareupdate” command, we see the following now:
[root@enkx4db03 ~]# dcli -l root -g cell_group cellcli -e 'list softwareupdate detail'
enkx4cel05: name: 18.1.1.0.0.171018
enkx4cel05: status: PreReq OK. Ready to update at: 2017-10-30T22:45:00-05:00
enkx4cel05: store: http://192.168.12.111
enkx4cel05: time: 2017-10-30T22:45:00-05:00
enkx4cel06: name: 18.1.1.0.0.171018
enkx4cel06: status: PreReq OK. Ready to update at: 2017-10-30T22:45:00-05:00
enkx4cel06: store: http://192.168.12.111
enkx4cel06: time: 2017-10-30T22:45:00-05:00
enkx4cel07: name: 18.1.1.0.0.171018
enkx4cel07: status: Checking Prerequisites
enkx4cel07: store: http://192.168.12.111
enkx4cel07: time: 2017-10-30T22:45:00-05:00
As you can see, 2 of the cells are ready to go, and enkx4cel07 is still running its prerequisite check. They are ready to update at 22:45 on Monday night, as I instructed them. During this initial phase, the patch files are downloaded to /var/swupdate/. If there are any issues with the prerequisite checks, you can find the logs in /var/swupdate//logs. There will be a file named .log that contains the output of the checks.
This rack is running a virtualized configuration – I currently have all of my clusters shut down, meaning that when the storage servers wake up to apply their patch, they should all be upgraded at once. This is due to the asmdeactivationoutcome attribute showing “Yes” for all griddisks. If my cluster were online, one of the the cells would elect to go first, beating the other 2. They will wait for the first cell to upgrade. When its griddisks are all back online and synced up, the race condition will begin again and repeat until all cells are patched.
Sure enough, patches are being applied to all of the cells at once:
[root@enkx4db03 ~]# dcli -l root -g cell_group cellcli -e 'list softwareupdate detail'
enkx4cel05: name: 18.1.1.0.0.171018
enkx4cel05: status: Running
enkx4cel05: store: http://192.168.12.111
enkx4cel05: time: 2017-10-30T22:45:00-05:00
enkx4cel06: name: 18.1.1.0.0.171018
enkx4cel06: status: Running
enkx4cel06: store: http://192.168.12.111
enkx4cel06: time: 2017-10-30T22:45:00-05:00
enkx4cel07: name: 18.1.1.0.0.171018
enkx4cel07: status: Running
enkx4cel07: store: http://192.168.12.111
enkx4cel07: time: 2017-10-30T22:45:00-05:00
If you look at the cell itself, the patchmgr script is being run out of the /var/swupdate/patch_18.1.1.0.0.171018 directory:
[root@enkx4cel07 ~]# ps -ef |grep patchmgr
root 14112 14100 0 22:45 ? 00:00:00 sh patchmgr -ms_update -cells cells -patch -rolling -log_dir /var/swupdate/patch_18.1.1.0.0.171018/logs
root 16544 6649 0 22:48 pts/1 00:00:00 grep patchmgr
Since the patch is being applied via the same scripts you’ve always used, you can still find log files during the patch on each cell in /root/_cellupd_dpullec_/_p_. After waiting for the cells to be updated, I checked and saw the following status:
[root@enkx4db03 ~]# dcli -l root -g cell_group cellcli -e 'list softwareupdate detail'
enkx4cel05: name: 18.1.1.0.0.171018
enkx4cel05: status: Last update completed at: 2017-10-30 23:03:55 -0500
enkx4cel05: store: http://192.168.12.111
enkx4cel05: time: 2017-10-30T22:45:00-05:00
enkx4cel06: name: 18.1.1.0.0.171018
enkx4cel06: status: Last update completed at: 2017-10-30 23:04:24 -0500
enkx4cel06: store: http://192.168.12.111
enkx4cel06: time: 2017-10-30T22:45:00-05:00
enkx4cel07: name: 18.1.1.0.0.171018
enkx4cel07: status: Last update completed at: 2017-10-30 23:04:03 -0500
enkx4cel07: store: http://192.168.12.111
enkx4cel07: time: 2017-10-30T22:45:00-05:00
Now, let’s look at what happens when CRS is up. I went ahead and rolled my cells back to 18.1.0.0.0 and sure enough, the attributes were reset to where they were before patching took place. If I want to try again with a rolling patch, I just need to ensure that CRS is running. I modify the start time, and we’ll see what happens:
[root@enkx4db03c02 ~]# dcli -l root -g cell_group cellcli -e 'alter softwareupdate time=\"9:20AM Tuesday\"'
enkx4cel05: Software update is scheduled to begin at: 2017-10-31T09:20:00-05:00.
enkx4cel06: Software update is scheduled to begin at: 2017-10-31T09:20:00-05:00.
enkx4cel07: Software update is scheduled to begin at: 2017-10-31T09:20:00-05:00.
Sure enough, at 9:20AM, the cells begin to patch. The new operating system is laid down on the inactive partitions, and the cells enter a race condition to determine who will be upgraded first. After watching /var/swupdate/patch_18.1.1.0.0.171018/logs/patchmgr.log, I can see it’s enkx4cel06:
[1509459611][2017-10-31 09:24:07 -0500][INFO][0-0][patchmgr][patchmgr_print_format_message][156] Working: Wait for cell to reboot and come online. Between 35 minutes and 600 minutes.
[1509459611][2017-10-31 09:24:07 -0500][INFO][0-0][patchmgr][patchmgr_print_format_message][156] enkx4cel06 will now reboot for software update. All terminal sessions will be closed.
Do not be disturbed by seeing what looks like an error in the patchmgr.log file – this is just the script logging that another cell has started the upgrade process and it will be in a waiting state:
[1509464109][2017-10-31 10:39:05 -0500][INFO][0-0][patchmgr][patchmgr_print_format_message][156] enkx4cel05 will now reboot for software update. All terminal sessions will be closed.
[1509464109][2017-10-31 10:40:35 -0500][ERROR][0-0][patchmgr][patchmgr_print_format_message][156] FAILED: For details, check the following files in the /var/swupdate/patch_18.1.1.0.0.171018/logs:
[1509464109][2017-10-31 10:40:35 -0500][ERROR][0-0][patchmgr][patchmgr_print_format_message][156] FAILED: - .log
[1509464109][2017-10-31 10:40:35 -0500][ERROR][0-0][patchmgr][patchmgr_print_format_message][156] FAILED: - patchmgr.stdout
[1509464109][2017-10-31 10:40:35 -0500][ERROR][0-0][patchmgr][patchmgr_print_format_message][156] FAILED: - patchmgr.stderr
[1509464109][2017-10-31 10:40:35 -0500][ERROR][0-0][patchmgr][patchmgr_print_format_message][156] FAILED: - patchmgr.log
[1509464109][2017-10-31 10:40:35 -0500][ERROR][0-0][patchmgr][patchmgr_print_format_message][156] FAILED: Wait for cell to reboot and come online.
[1509464109][2017-10-31 10:40:35 -0500][ERROR][0-0][patchmgr][patchmgr_print_format_message][156] Patch failed. Please run cleanup before retrying.
While enkx4cel06 is being patched, I check the softwareupdate value to see what’s happening:
[root@enkx4db03c02 ~]# dcli -l root -g cell_group cellcli -e list softwareupdate detail
Unable to connect to cells: ['enkx4cel06']
enkx4cel05: name: 18.1.1.0.0.171018
enkx4cel05: status: Running
enkx4cel05: store: http://192.168.12.111
enkx4cel05: time: 2017-10-31T09:20:00-05:00
enkx4cel05: timeLimitInMinutes: 30
enkx4cel07: name: 18.1.1.0.0.171018
enkx4cel07: status: Running
enkx4cel07: store: http://192.168.12.111
enkx4cel07: time: 2017-10-31T09:20:00-05:00
enkx4cel07: timeLimitInMinutes: 30
We cannot connect to enkx4cel06 (it’s currently being patched), and the other cells show a status of “Running” – they’re actually waiting for the active cell to complete. As soon as that cell’s disks are back online, the remaining cells restart the race and continue moving along until every cell is finished.
One feature that I would like to see is an email alert that opens when a storage server begins patching and a “cleared” message when it is complete. With the current process, updates are completed silently.
When rolling patches fail
What will happen to a cell if the rolling patch fails? Cell patches could fail for any number of reasons – firmware upgrade issues, disk failures, or if the “timeLimitInMinutes” attribute is exceeded. In that case, administrators will receive an email alert (determined by the smtpToAddr attribute for the cell) saying that the patch has failed.
Also, the softwareupdate status will be marked as failed:
[root@enkx4db03c02 ~]# dcli -l root -g cell_group cellcli -e list softwareupdate detail
enkx4cel05: name: 18.1.1.0.0.171018
enkx4cel05: status: Upgrade failed. See alerts
enkx4cel05: store: http://192.168.12.111
enkx4cel05: time: 2017-10-31T09:20:00-05:00
enkx4cel05: timeLimitInMinutes: 30
enkx4cel06: name: 18.1.1.0.0.171018
enkx4cel06: status: Last update completed at: 2017-10-31 09:39:22 -0500
enkx4cel06: store: http://192.168.12.111
enkx4cel06: time: 2017-10-31T09:20:00-05:00
enkx4cel06: timeLimitInMinutes: 30
enkx4cel07: name: 18.1.1.0.0.171018
enkx4cel07: status: Upgrade failed. See alerts
enkx4cel07: store: http://192.168.12.111
enkx4cel07: time: 2017-10-31T09:20:00-05:00
enkx4cel07: timeLimitInMinutes: 30
You can see the alert in further detail with the “list alerthistory” command in cellcli:
CellCLI> list alerthistory 493_1 detail
name: 493_1
alertMessage: "The software update for 18.1.1.0.0.171018 failed."
alertSequenceID: 493
alertShortName: Software
alertType: Stateful
beginTime: 2017-10-31T09:50:16-05:00
examinedBy:
metricObjectName: SW_UPDATE_UPDATE
notificationState: sent
sequenceBeginTime: 2017-10-31T09:50:16-05:00
severity: critical
alertAction: "Correct the problems shown in the attached log files, and then run: ALTER SOFTWAREUPDATE UPGRADE and verify that these problems are fixed. Diagnostic package is attached. It is also accessible at https://enkx4cel07.enkitec.local/diagpack/download?name=enkx4cel07_2017_10_31T09_50_16_493_1.tar.bz2 It will be retained on the storage server for 28 days, after which it may be automatically purged by MS during accelerated space reclamation. Diagnostic packages for critical alerts can be downloaded and/or re-created at https://enkx4cel07.enkitec.local/diagpack"
In this case, the ASM disk resync lasted too long and the “timeLimitInMinutes” attribute timed out. We have 2 options to restart the patch:
- Force the patch to restart on the unpatched cells immediately via the “alter softwareupdate update” command
- Modify the schedule with “alter softwareupdate time=” to schedule a new time for patching to be executed
The option you take will depend on what caused the failure on your side. If you need to wait for another slow period to restart the upgrade, you are better off setting the schedule attribute and letting the cells proceed on their own.
Overall, while I am a creature of habit, I can definitely see the benefits of this change. While many customers running smaller eighth/quarter rack configurations may continue to use patchmgr, this will be a welcome change for larger Exadata environments. I’m also very happy to see this utilize the existing underlying technologies rather than trying to reinvent the wheel with the patching process.
I asked about the email to development and they said that when upgrading large number of systems, the operators did not want an email alert for success but just on failures to keep the inbox tidy.
That makes sense. It would be nice to have a flag to turn that on or off, but I definitely understand why. One of the great things about storage server alerts is that they aren’t overly chatty.