One of the cool things that Oracle has done with Exadata is give users the ability to upgrade from Oracle Linux 6 to Oracle Linux 7 with an in-place upgrade process. This comes automatically when you upgrade the Exadata compute image from 18c to 19c. Upgrading the compute nodes to 19c give you the ability to upgrade your grid infrastructure to 19c, followed by installing a 19c database home and beginning the database upgrade process.
The compute node upgrade is done using the same tools as a normal Exadata operating system patch, either via dbnodeupdate.sh or its wrapper script, patchmgr. As part of the process, the server will go through a couple of reboots and perform some actions, during which time the SSH daemon is shut down. Normally, this blackout only lasts for 30 minutes. This always reminds me of the Apollo 13 reentry, where the normal communications blackout lasted nearly twice what it normally would.
I’ve seen a handful of upgrades where the system seemed to be completely stuck. Connecting to the serial console gave me the following output – hitting enter didn’t move the cursor, and I couldn’t see any activity for more than an hour:
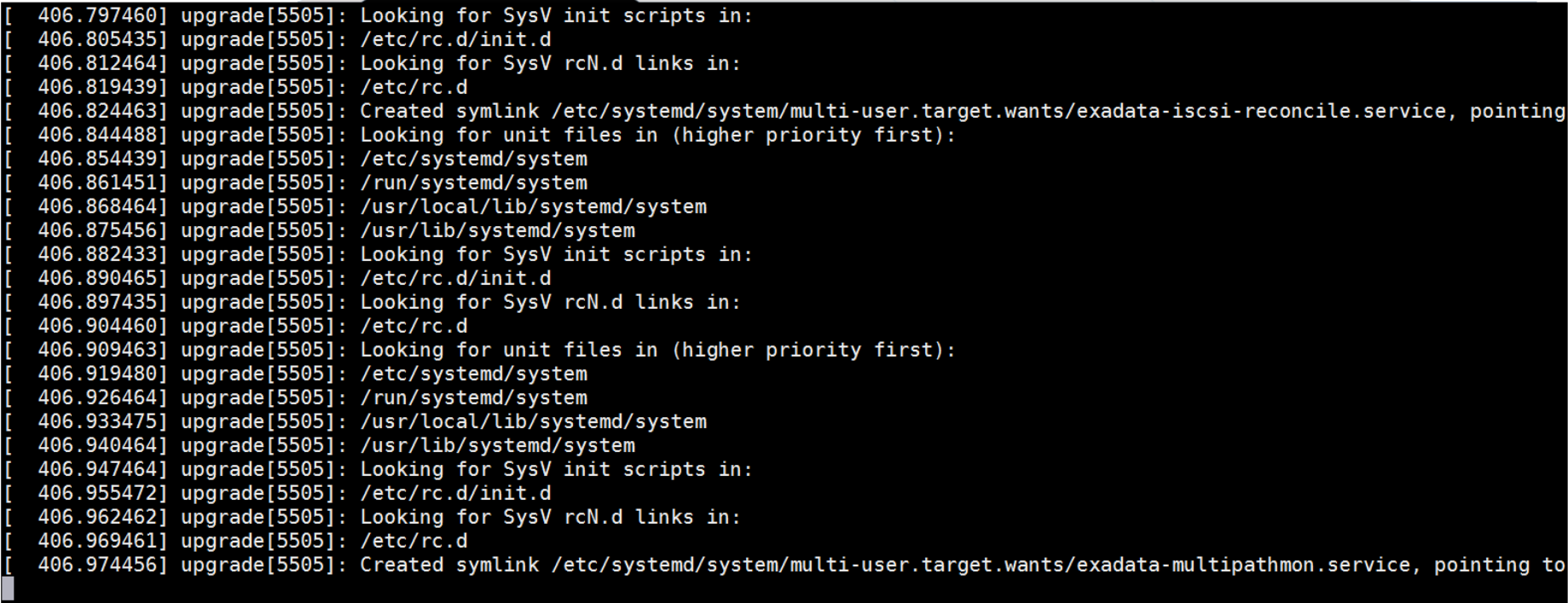
I remembered after looking at the serial console that the upgrade process performs a kexec reboot with different options than a normal boot, so more text actually shows up in the Java-based console from the ILOM’s web interface. Looking there wasn’t much more help:
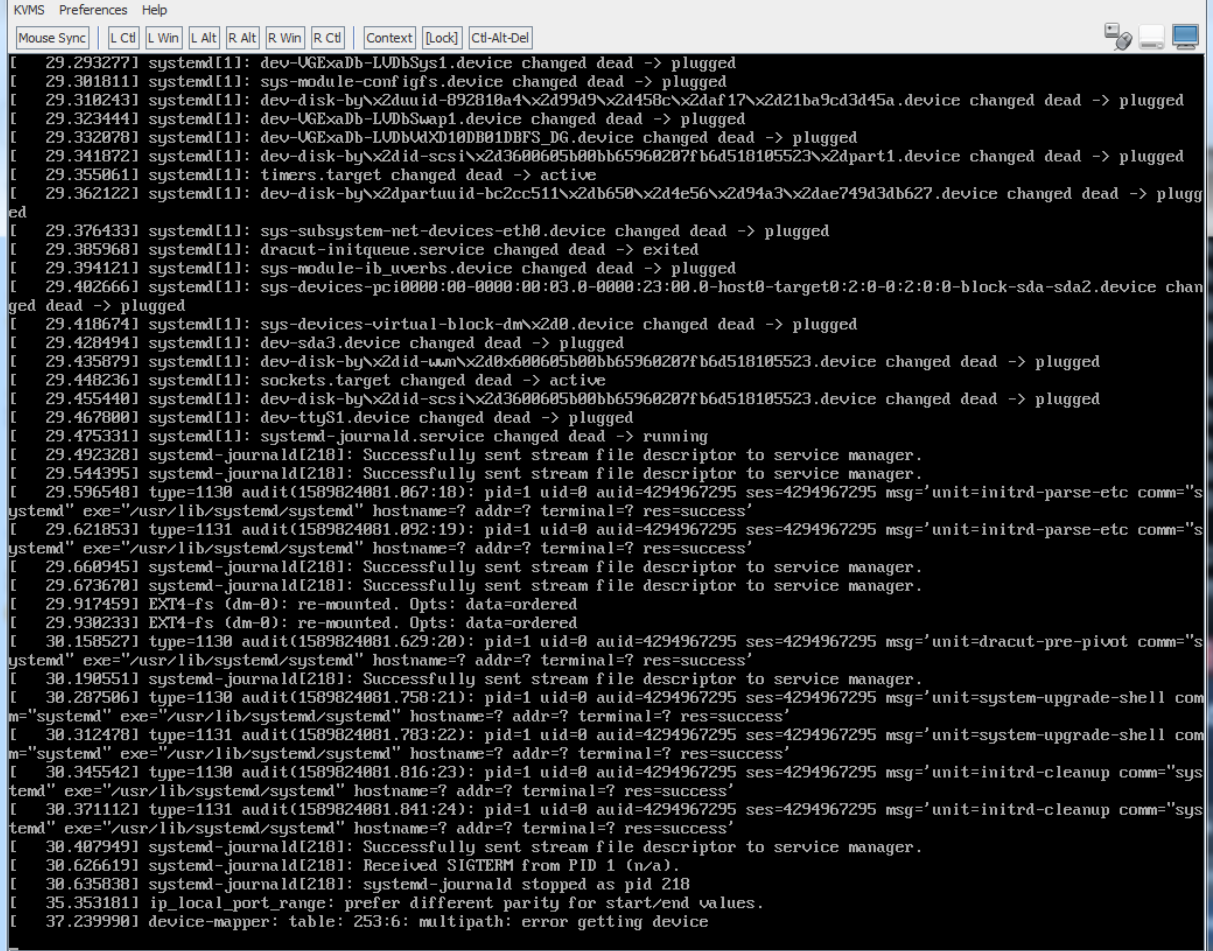
The system sat here for a long time as well, seemingly stuck. I had two options – force a reboot through the ILOM, or wait out the upgrade process to see if it would go through. I’d gone through the reboot option before, but that left me with a host requiring a manual restore from the backup taken by dbnodeupdate.sh, so I decided to wait it out and see what happens.
I remembered that with the Java console, I have the option to hit alt-F2 to go to the second console screen. Thankfully, that worked, and I was presented a bash prompt. I tried to run a few commands, but not much was available in the path. I discovered that the root volume of the host was mounted as /sysroot, and could find the patch logs in /sysroot/var/log/cellos/exadata.computenode.post.log. From there, I could run “/sysroot/bin/tail -f” on the log file, and see what was happening:
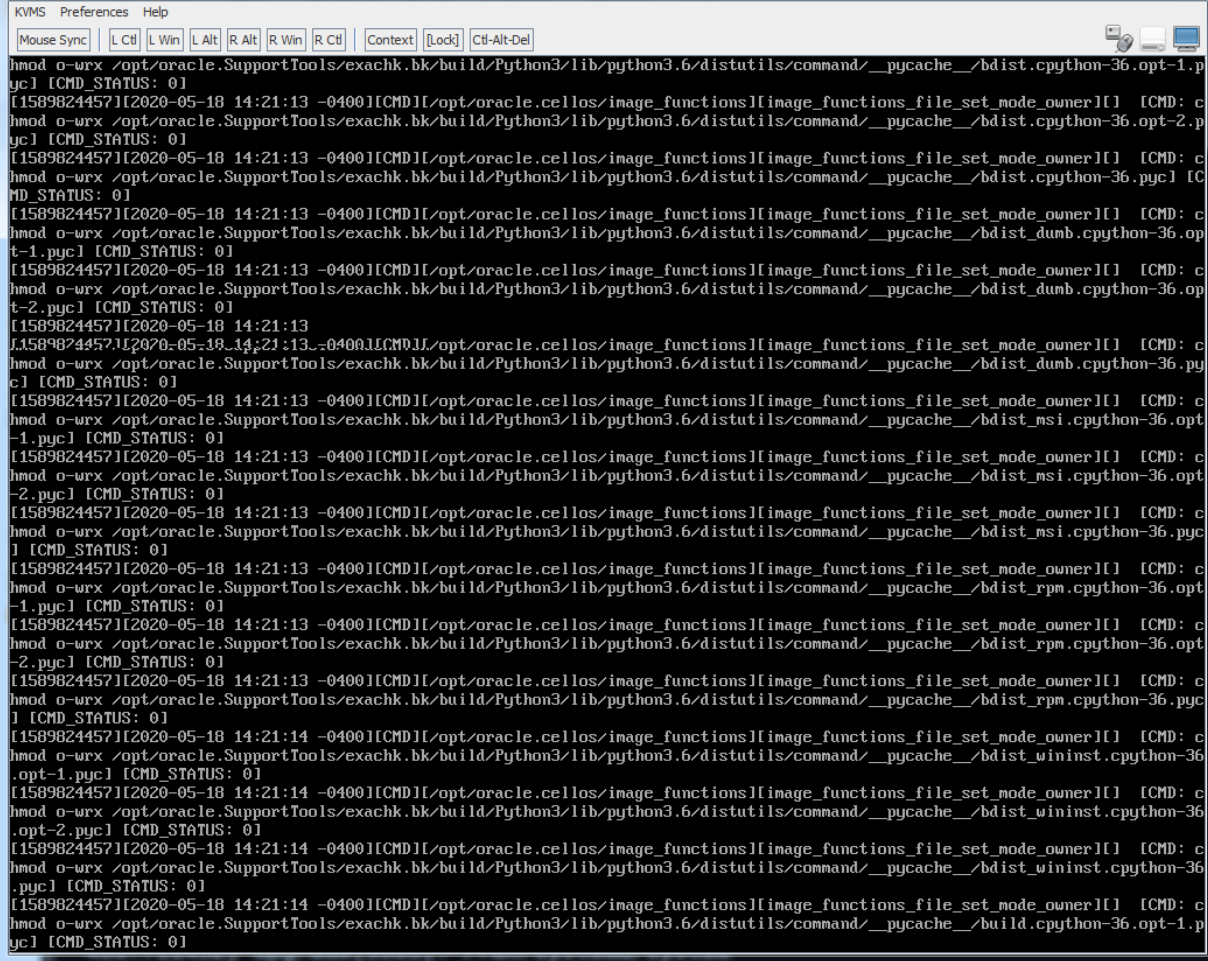
There we have it – as part of the upgrade, the /opt/oracle.cellos/image_functions script removes global read, write, and execute permissions on files in a handful of directories, including /opt and /usr. This process changes permissions one file at a time. Even though it’s a quick process, directories like exachk can have tens of thousands of files inside. Just like any other row-by-row processing, even a quick operation done too many times will slow you down. This tracks back to Oracle bug #30365408, which skips the /opt/oracle.SupportTools/exachk directory. Unfortunately, the system in question here had a backup of the exachk directory found in /opt/oracle.SupportTools/exachk.bk. This directory wasn’t skipped, and it added about an hour to go through the 95,000 files in that directory. Thankfully, the script times out after 150 minutes, but that can still blow out a maintenance window if you’re not careful.
Older versions of exachk seem to be the biggest offenders, and they typically only exist on the first node of a cluster. If it’s possible to clean up anything sitting in /opt, definitely add that to your pre-patch checks before going through the upgrade to Oracle Linux 7.
All in all, as with most patching activities, it’s best to wait out the process for a full failure before jumping in and trying to nudge the system along the way.
It’s still true that the hardest thing with exadata patching is sitting on your hands and waiting out the patch process to finish.
Exactly – sometimes it can be really hard to sit and wait it out.